


编辑:李信马
头图:豆包AI
DeepSeek的火爆有目共睹,自春节假期期间在社交媒体上引发广泛讨论,当下正以迅猛之势向各个行业渗透。随着“XXX接入DeepSeek”的消息如雪花般飞来,接入DeepSeek似乎成为当下拥抱AI的“先进”标志。

图源:DeepSeek截图
随着腾讯、百度、阿里、字节等大模型第一梯队的大厂们都相继宣布接入DeepSeek,“AI六小虎”中的阶跃星辰和MiniMax等也都做出了同样的选择。
但有意思的是,腾讯、百度、阿里、字节等接入DeepSeek的程度不同。
对比来看,腾讯、百度接入DeepSeek最“深”。除了业务侧产品(像腾讯的微信、腾讯文档、QQ浏览器,百度的百度搜索、百度智能云旗下应用产品等),自研的AI助手腾讯元宝、文小言(原文心一言)也都接入了DeepSeek-R1。
阿里则是业务侧产品接入了DeepSeek,像钉钉支持用户使用DeepSeek 系列模型创建钉钉AI助理、定制智能多维表格,阿里云百炼平台上线全尺寸DeepSeek模型,以及1688宣布将基于DeepSeek开发生意大模型,但给自研的大模型产品通义千问还是留有一部分独立空间。
而字节对于DeepSeek的接入相对最“浅”,仅有火山引擎及其旗下产品和飞书官宣上线了DeepSeek系列模型。但一般来说,云平台通常会提供多种大模型供用户选择和使用,以满足不同的应用需求。火山引擎旗下的大模型服务平台火山方舟在此前,也上架了除自家豆包外的其他大模型,像智谱AI的GLM 模型、月之暗面的Moonshot等。至于飞书,准确来说,是飞书的多维表格中接入了 DeepSeek R1。
接入的最“浅”,是否意味着字节最为“自信”?认为其自研模型能达到或是赶超DeepSeek的水平?
2 月 13 日,字节举办了新一期的 All Hands 全员会上,关于DeepSeek的现象级热度,字节 CEO 梁汝波反思的同时,强调了2025年的重点目标:追求 “智能” 上限,关注关键技术,字节的应对策略透露出战略级的调整。
前几天又有消息称,前谷歌大牛吴永辉加入字节跳动担任大模型团队Seed基础研究负责人,进一步释放其坚持自研大模型的信号,未来,字节AI能否又后来居上呢?
01、迟到的入场与资本驱动的反超
字节有这样的发展思路其实并不令人意外。毕竟,其旗下的豆包大模型在过去一年里已经上演了一场“后来者居上”的逆袭剧情。
时间回溯到2022年11月,ChatGPT发布后在全球掀起了一场AI浪潮,国产大模型也随之迎来了爆发期。2023年,众多大厂和创新型企业纷纷亮出自研大模型产品,比如百度的文心、阿里的通义千问1.0、腾讯的混元、360的智脑、华为的盘古、科大讯飞的星火、商汤的日日新、百川大模型,以及智谱AI的GLM等,一时间群雄逐鹿,好不热闹。
然而,直到2023年1月,字节的大模型研发团队才正式成立。
反应过来的字节,在7个月后,推出自研的“云雀”大模型(后更名为“豆包”),同时还推出了一款多模态大模型——BuboGPT。在之后的大模型“价格战”中,更是打出响亮的一枪。

图源:火山引擎原动力大会图片
进入2024年,为了在大模型追逐战里抢占先机,字节一方面四处挖人:先后挖来了零一万物原预训练负责人黄文灏、Google 原 VideoPoet 项目负责人蒋路等。10 月份,还被曝出以八位数年薪的豪爽手笔挖走了阿里通义千问技术负责人周畅。
另一方面,字节倾注全系流量推广豆包APP。2024年3月18日,抖音巨量广告发布公告,限制AIGC软件投流,从4月2日到年末,非字节系产品无人能使用抖音、头条的巨大流量池。而根据AppGrowing的数据显示,豆包智能助手在去年4月、5月的投放金额接近1800万元,到6月上旬,这一数字飙升至1.24亿元。在字节这种不计成本的投入下,成功让豆包成了月活7000万的国内头部AI APP。
如果以往的经验,这一赛道上,同行想要追赶上豆包恐怕是难上加难。
据浙商证券研报显示,字节在 AI 领域的投入堪称大手笔,2024 年的资本开支高达 800 亿元,这一数字接近百度、阿里、腾讯三家总和(约 1000 亿元),研发投入显著领先于同行竞争对手。有媒体报道称,字节计划在2025年投入超1500亿元用于资本支出。
另一方面,字节跳动早些年在移动互联网时代积累下的成功 To C 经验,如今也转化为了其独特的差异化优势。相较于竞争对手,字节拥有更为丰沛海量的流量资源,能够为落地应用的快速起量提供强有力的支撑保障。
据不完全统计,字节在2024年发布了接近20款AI应用,基本覆盖了图像、语音、音乐、视频、3D等主流模态和场景。这种“饱和式”打法,让字节成为AI领域“军火库”最齐全的科技公司之一。
02、DeepSeek重新定义游戏规则
然而,DeepSeek的出现,却改变了行业以往的规则。
首先,C端发生了肉眼可见的变化,随着DeepSeek接连发布V3模型和R1模型后,豆包在过去一年建立的DAU优势,瞬间被瓦解。据QuestMobile数据显示,DeepSeek在1月28日的日活跃用户数就首次超越豆包,2月1日突破3000万大关。且快速增长的用户日活还没“花钱”。用影视圈的说法是,全是“自来水”。
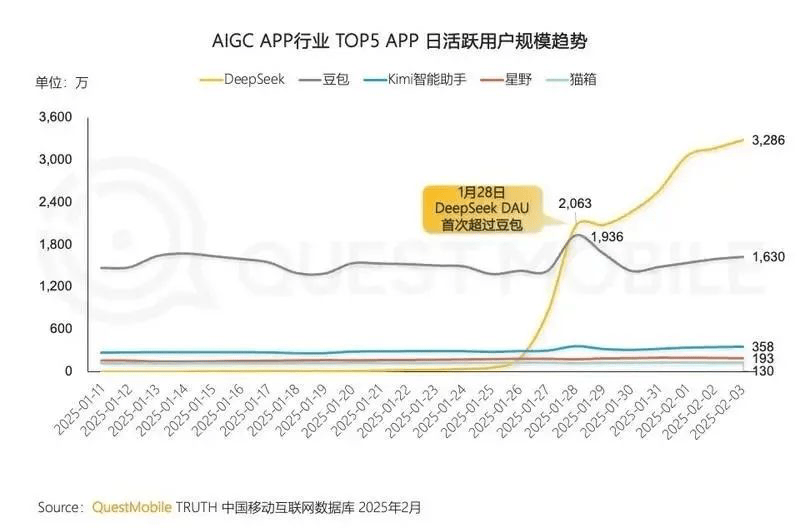
让DeepSeek从豆包、Kimi等AI智能助手App中脱颖而出的,除了其对指令的理解以及答案的更为准确外,还有它出色的思维链(Long-CoT)能力。
不同于以往的AI大多只给结果,DeepSeek模型能够展示思考过程,包括问题复述、回顾反思、知识调用(结论的来源和引用的网站等关键信息)与公式化等环节等。透明的思考路径既为用户提供了深入了解模型推理细节的机会,也能够增强用户对 AI 系统的信任。
而自1月份开始,阿里、科大讯飞、百川智能、月之暗面等AI企业,也开始密集为旗下模型升级了深度思考能力。

图源:KIMI截图
当然,除了思维链模型,DeepSeek身上还有开源模式和低算力需求的优势。前者降低了进军AI领域的技术门槛,后者在保持高准确性的同时显著降低了内存占用和计算开销。这也使得DeepSeek在to B端更有性价比。
DeepSeek技术上突破所带来的优势,打破了此前国内市场的竞争格局与规则,科技大厂们似乎又回到同一起跑线。
面对新的游戏规则,相比百度、阿里、腾讯果断接入DeepSeek的态度,字节的选择确实更难。也选择深度拥抱DeepSeek,那么此前建立的优势可能会功亏一篑;如若不,就意味着要和DeepSeek“硬刚”。
字节当下所展现出的态度,似乎更像是选择 “硬碰硬” 式的应对。在其全员会的前两天,豆包大模型团队还提出了全新的稀疏模型架构UltraMem,推理速度较MoE架构提升2~6倍,推理成本最高可降低83%,看起来颇有剑指 DeepSeek 核心优势的意图。
长远来看,字节未必没有胜算,上文的竞争规律在新一轮的赛程中同样适用。在技术侧的迭代和升级速度上“持久战”,以及做好大模型技术与各类应用、场景的深度融合工作。
字节过去一年在应用端已经打下一定基础,在技术侧方面,当下 “智能上限” 更高的 DeepSeek,同样得直面技术迭代挑战。
不过就当下情况来看,字节似乎处于比较被动的境地。通过接入DeepSeek,腾讯已经在C端用户的争夺上展现出了赶超势头。从2月22日开始,腾讯旗下的AI应用“腾讯元宝”,就超越了豆包,跃居中国区苹果应用商店免费APP下载排行榜第二位,并一直维持至今。

图源:七麦数据
阿里也在DeepSeek带来的新局面下,开始加大AI技术方面的投入。阿里集团CEO吴泳铭在2月20日晚财报电话会上称:“未来三年在云和AI的基础设施投入预计将超越过去十年的总和。”
扩大到全球范围,在DeepSeek的刺激下,更多科技公司开始提速。如果不能尽快推出新的可以媲美DeepSeek的自研推理大模型,字节接下来或许将会更加的被动。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






