


雷递网 乐天 1月26日
DeepSeek正成为AI领域崛起的“黑马”。DeepSeek的横空出世,打破了国内大模型原有格局。
本周,DeepSeek发布 DeepSeek-R1,并同步开源模型权重。DeepSeek-R1遵循MIT License,允许用户通过蒸馏技术借助R1训练其他模型。
DeepSeek-R1 上线 API,对用户开放思维链输出,通过设置 model=’deepseek-reasoner’ 即可调用。
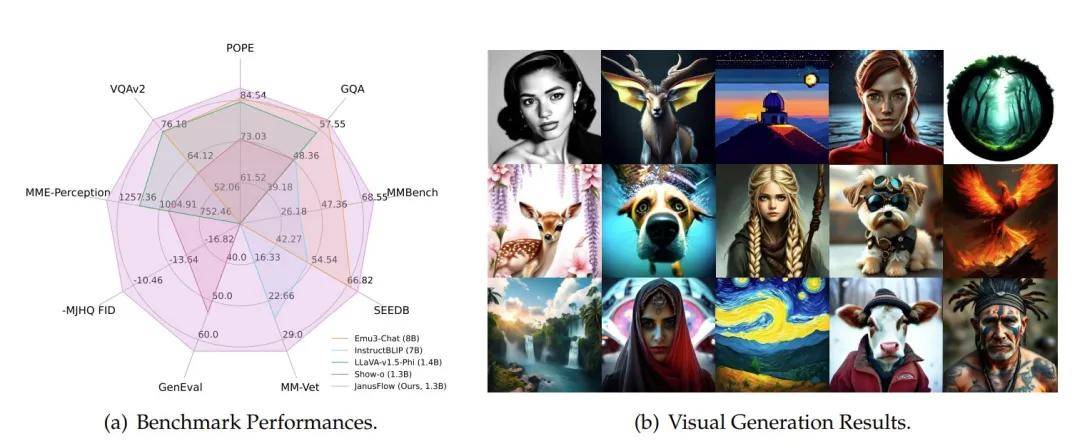
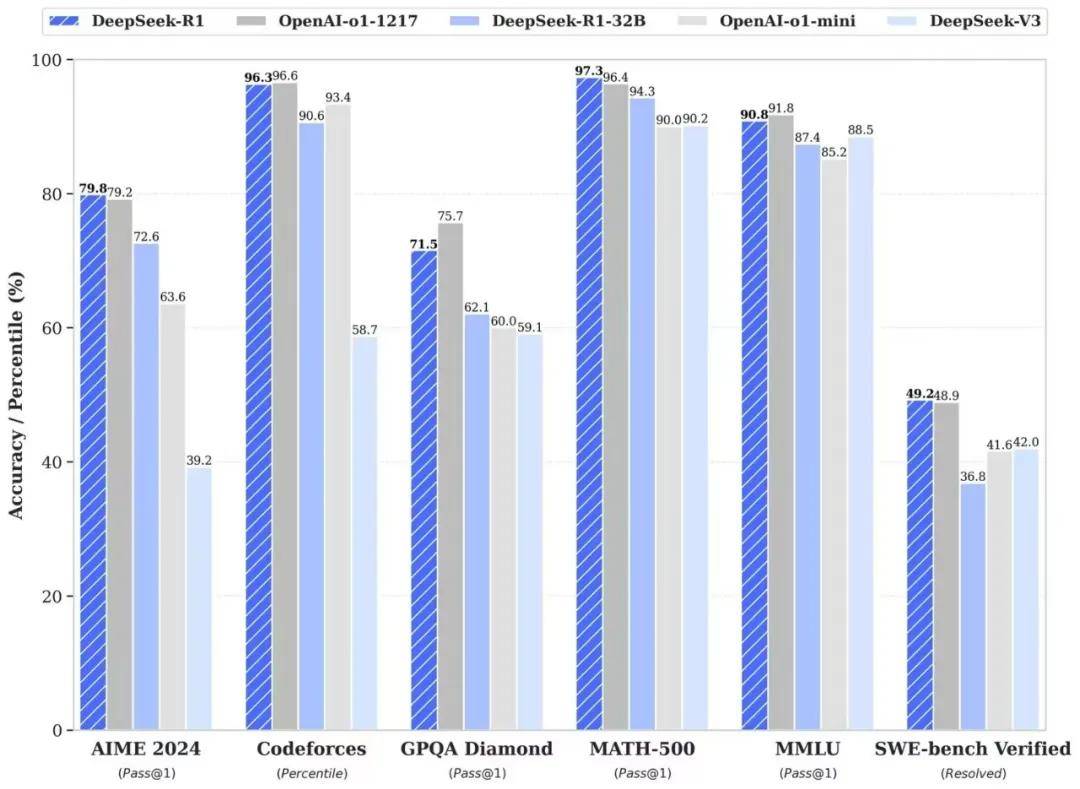
DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。
DeepSeek-R1在开源DeepSeek-R1-Zero和DeepSeek-R1两个 660B模型的同时,通过 DeepSeek-R1 的输出,蒸馏6个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标OpenAI o1-mini 的效果。
DeepSeek-R1 API 服务定价为每百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 tokens 16元。
DeepSeek震动美国科技界,不仅是因为其性能上比肩OpenAI的o1,并完全开源,且以极低的成本实现了这一突破。
知名投资人马克·安德森也表示:“DeepSeek R1 是我见过的最令人惊叹和印象深刻的突破之一,作为开源项目,这是给世界的一份重要礼物。”
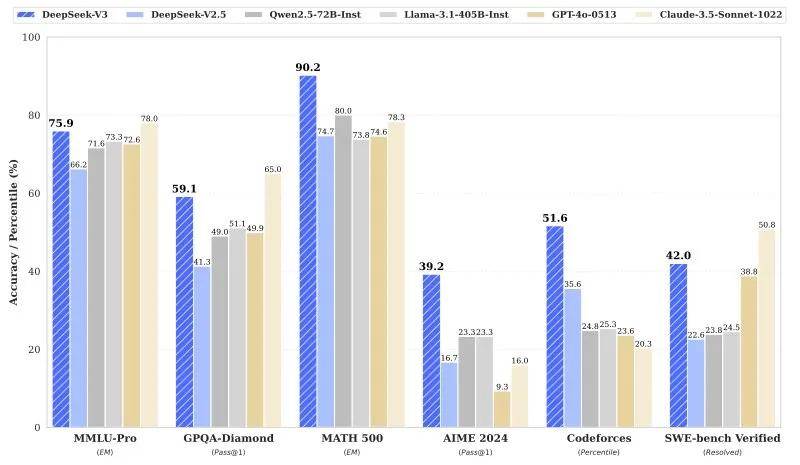
AI科技初创公司Scale AI创始人亚历山大·王(Alexandr Wang)称,过去十年来,美国可能一直在人工智能竞赛中领先于中国,但DeepSeek的AI大模型发布可能会“改变一切”。DeepSeek的AI大模型性能大致与美国最好的模型相当。

Alexandr Wang认为,DeepSeek-R1与GPT-4o和Claude 3.5 Sonnet 相当,训练时计算量减少10倍。DeepSeek-V3展示给外界的教训是:在美国人休息时,中国人在工作,并以更便宜、更快、更强的产品迎头赶上。
“The bitter lesson of Chinese tech: they work while America rests, and catch up cheaper, faster & stronger。”
Alexandr Wang出生于1997年,他于19岁那年从美国麻省理工学院辍学创立公司,如今,Scale AI估值超百亿美元,获得包括Y Combinator、英伟达、AMD风投、亚马逊、Meta等投资,该公司为OpenAI、谷歌和 Meta等提供训练数据。
DeepSeek的动作让Meta的生成式AI团队陷入恐慌。Meta CEO扎克伯格宣布加速研发 Llama 4,计划投资650亿美元扩建数据中心,并部署130万枚 GPU 以“确保2025年 Meta AI 成为全球领先模型”。
DeepSeek创始人梁文锋也迅速奠定在AI圈地位。
据介绍,梁文锋本硕均就读于浙江大学信息与电子工程学专业。2015年,梁文锋与校友共同创立幻方量化。2021年,幻方量化成为国内首家突破千亿规模的的量化私募大厂,被称为国内量化私募“四大天王”之一。
早年,幻方量化开始大规模布局 AI 算力,搭建起“萤火一号”集群。2021年,“萤火二号”落成,这给了DeepSeek快速奔跑的底层支撑。
有评论人士称,中国股民给世界AI最大的的贡献就是让幻方量化赚了那么多钱。然后幻方量化创始人有钱买最好的GPU,收纳一批中国最牛的精英,做出了不错的Deepseek。
预训练方面,DeepSeek团队的贡献在于超强的训练稳定度、深入使用fb8混合精度、多词同时预测、隐空间多注意力头,MOE混合专家等大大降低训练成本,用600万美元训练一个600B的大模型,被是工程上的奇迹。

分析人士指出,DeepSeek用10-15分之一的成本就训练出比肩Openai o1水平的模型R1,而R1还都开源,这意味着算法有太多提高空间,不需要那么多GPU,不需要那么多算力,封锁芯片,搞算力壁垒的思路行不通,而OpenAI和Meta等美国企业靠GPU堆砌效果的模式也大打折扣。
DeepSeek还可能形成一个效应,那就是很多购买了数千块NVIDIA芯片的AI初创公司都可能破产,从而导致大量NVIDIA GPU 流入二手市场。此外,还有一些初创公司的模式是运营数据中心(例如Coreweave),并将NVIDIA GPU 出租给其他公司,以期获得投资回报。最后,七巨头最终将开始放缓或削减来自NVIDIA的未来订单,有关NVIDIA的一切都会开始瓦解。
这可能刺激更多专用推理模型诞生,而创业公司、个人App等可能会大幅减少在OpenAI API上的支出,转向开源。
另有评论人士称,DeepSeek的横空出世,体验后发现其整合搜索信息的能力强于豆包,令人对英伟达股价的支撑产生怀疑,这会让美国公司赖以维持的技术优势和高估值可能会受到挑战。而国内大模型也显得尴尬,文心一言起了个大早,Kimi赶了个晚集,豆包左右失策。
有人总结说,中美科技底层差距虽然大,但中国拥有巨大人才红利,6000万工程师,超美德日韩印总和。人才红利是继续发展的底气和希望。
———————————————
雷递由媒体人雷建平创办,若转载请写明来源。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






