


文 | 李智勇
如果我们把产业的发展看成是一个技术、产品、模式不停转动深入的过程,那自chatGPT发布到o3可以看出是一个阶段,而o3之后可以看成一个阶段。
o3作为分水岭其意义在于,在到o3这种水平之前核心问题是模型好使不好使,在此之后的核心则是到底怎么让o3水平的模型发挥效力。(不是说模型不需要发展)
发挥效力的时候,如果只是从技术本身看待AI的挑战,看到的会全是提示词怎么写,这与AI会大范围提供通用智能的本质特征是错位的。
一定需要从此延展纵深到更大的空间才可能理顺应用通路,显然的萝卜快跑事件不是来自于技术和产品,但它确实影响产品化的进程,而每个落地情景可能都面对小微型的萝卜快跑式困境。
那在这个应用通路中什么最关键?
第一是AI和人的关系问题
这是未来各种应用塑形的基础和原点,在2024.12.29的AI碰撞局上北大国发院的侯宏老师提出了一个思考框架:
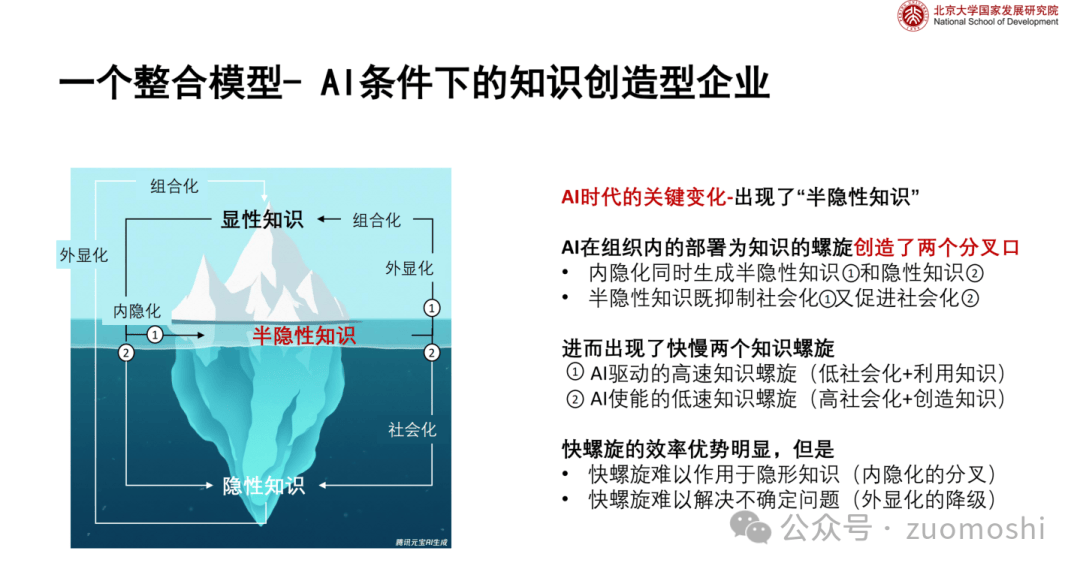
可能不好理解,但本质是在说知识创造过程中如何界定人与AI的关系(更多相关文章大家可以参照侯老师的公号:)。
关注知识创造和流转正是它成为一个原点问题的的原因。
因为在知识创造的过程中人、机的角色边界最终就会变成应用的边界的决定因素之一。
人机是横向切分的视角,如果再配上数据可获取范围的纵向视角,那基本就是AI应用的潜在格局。
人、机边界决定了应用的形态和深度,决定到底以什么方式给个人、企业提供智能,比如是Copilot还是Autopilot。
数据可获取边界则决定了角色的功能边界,到底提供什么,比如是教育还是法律还是其它。
第二,数据的可获取性
如上所说,数据的可获取性决定应用的功能边界。
这里的关键有两个:
一个是利益的各相同性,否则就不可能有源源不断的数据,没有源源不断的数据也就不可能越做越好,最终就只有低垂的果实。比如你给法院提供方案,那显然数据没法源源不断,这不是各技术问题,而是个生产关系重构的问题。需要复杂思考才可能找到一条真正可能的通路。
一个是数据自身的成本,成本是指长期确保高精度数据所要付出的成本。这个搞不好相当于一个强大的AI周边全是说假话的,它就不可能好使。
对于产品而言,这两个都是个战略问题,和后天努力关系不大,它先天决定产品的最终扩张的时候的边际成本。
如果我们把AI应用归为两个类别,一个是创造新效能,一个是创造新体验,对于前者上面说的生死攸关。
第三,数据通路的通用性问题
我们知道AI大模型的核心特征是能力的通用性。
我们假设AI大模型扮演大脑的角色,那这个脑子显然既能收玉米也能摘桃子,可如果实际干活的时候如果触手只有一种,比如像章鱼一样的爪子,那它就不能收玉米,只能摘桃子。
这时候不是模型能力不行,而是感知反馈通路的通用性不够,两者错配。
这是和过去应用的核心差异。
只要数据通路没问题,AI可以提供任何功能,关键的不再是功能。
第四,AI应用一定是系统型应用
AI应用没有小而美一说,因为数据的边界是应用的边界,小范围根本没壁垒,要么被大模型本身吸收掉,要么被同类别的应用吸收掉,只有极短的窗口期。
每个可能都和搜索、微信差不多,最终NO1的几乎占据所有。
而一旦数据通路的通用性变关键,就会导致应用往系统化方向发展,因为源是多的,需要表现出来的能力是需要动态变化的。前者衍生类似过去的硬件抽象层(HAL),后者衍生出来技能商店,这样一来中间就比如有调度器(Scheduler)等作为kernel。
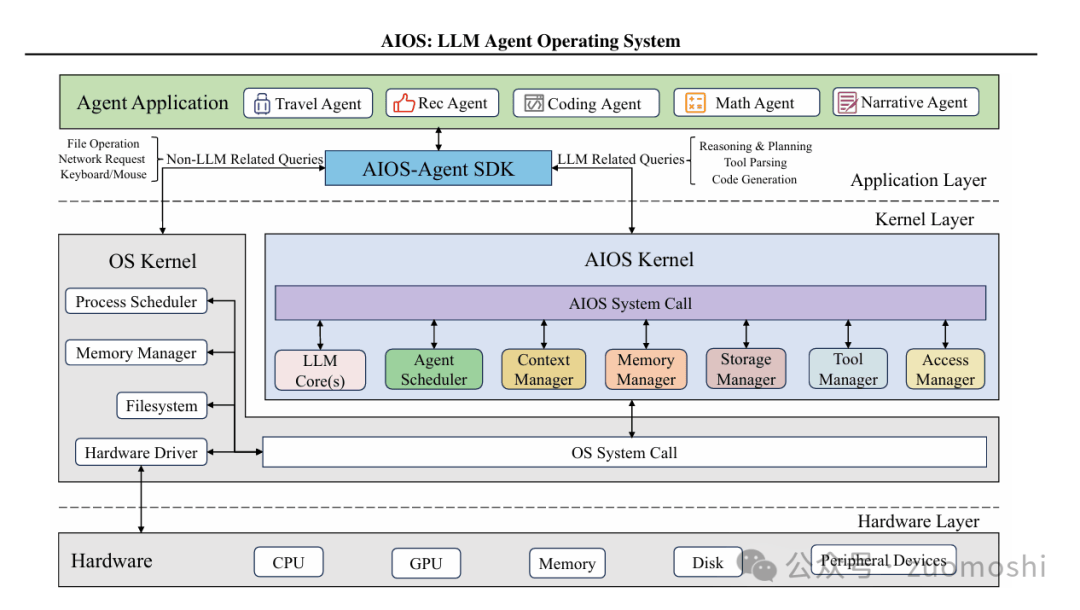
- 参见:https://arxiv.org/pdf/2403.16971
自动驾驶和过去最大的区别是它的自适应。
而所有未来的应用几乎都是需要具备自适应能力。
当累积足够的全场景数据后,会有两种进化模式一种则类似这种端到端的模型,这时候模型和应用是不分的,数据回来会贡献于更好的模型。
但还有一种情况则是更大量级的数据和更长的分析时间,可以得出更好的方案(利用o3的能力)。
显然的,这时候系统的内核则会划分成两个部分,一部分负责快思考,一部分负责慢思考。
对于系统型应用它绝大部分功能是自主完成的。这时候一部分是要实时处理各种响应,一部分则是要迭代并总结自己的行为进行改善。这两个活显然是要分开做的。所以系统型应用的kernel部分,需要双系统分立。

- 参见:https://arxiv.org/pdf/2410.08328
也许写的看起来有点夸张和独断,但这是一种必然性的脉络,这种脉络很像方法的方法,往往不以人的意愿而改变。我应该还是有点资格这么说,参见:,这是前面做的脉络判断,大致是准的。
- 补充说明:
上面的论文能看看思路,实际做有问题的。
1. 系统肯定不是在现在系统上的增强,而是现有系统之上的再定义,所以和现有系统的关系大概率不对。
2. 双系统的例子不好,它那例子不需要双系统。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






