


搜狐科技特约作者|Meta 科学家许家骏博士
编辑|杨锦
如果说近几年的 AI 发展如同电影般跌宕起伏,那么 DeepSeek 这个名字无疑是最近最惊艳的“新片”。
就在昨天,我在加州DMV(车辆管理局)排队时,前后排的大妈都在热烈讨论 DeepSeek 最新推出的开源模型 R1。要知道,本来科技话题很少在大妈的寒暄里出现,没想到瞬间 DeepSeek 占据了主角位置。
一个中国团队引发的“AI 黑天鹅”
DeepSeek 的新模型 R1 在短短两个月之内,用不到 600 万美元的预算,借助并不算顶级的 H800 芯片,就实现了可以与 OpenAI 等国际领先大模型“平起平坐”的性能。
业界普遍认为,这是连英伟达(NVIDIA)和 OpenAI 都未曾预见的“黑天鹅事件”。这种“以小博大”所释放的震撼不仅仅是技术层面,也给资本市场带来余震。
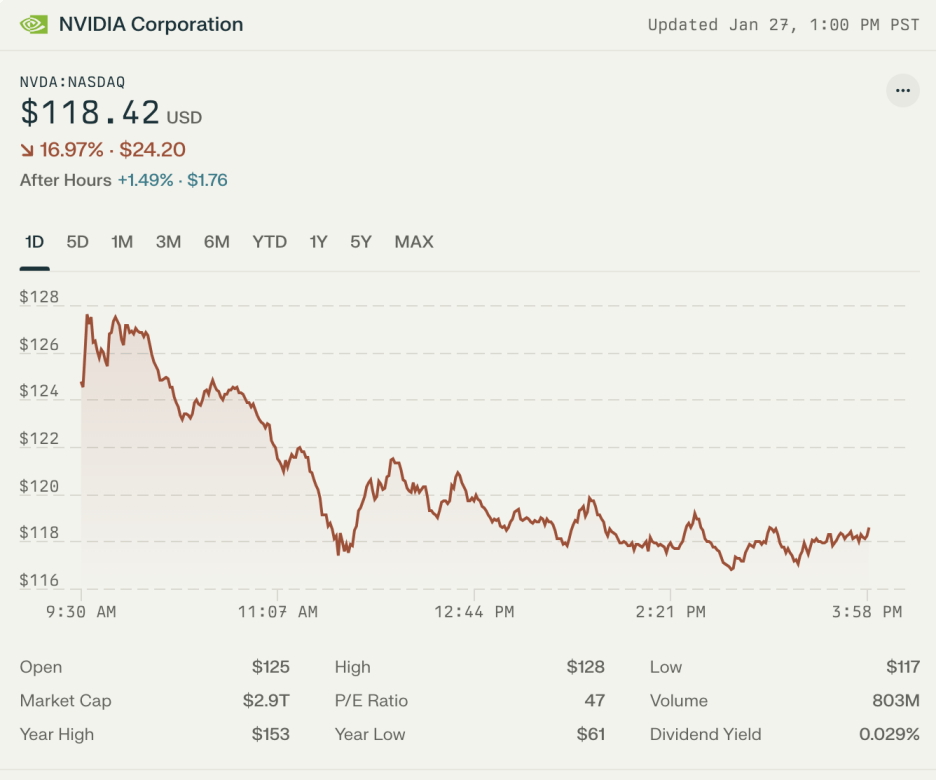
1 月 27 日,英伟达股票经历了自成立以来最惨烈的一次下挫,单日跌幅达到 17%,收盘价跌至 118.58 美元,蒸发约 6000 亿美元市值——创下美国上市公司单日市值损失最高纪录。
更令人惊讶的是,这股恐慌还蔓延至整个芯片产业:Broadcom 下跌 17%,ASML 下跌 6%。华尔街分析师指出,DeepSeek-R1 引发了市场对 AI 芯片需求可持续性的担忧。
曾经所有人都憧憬 GPU 需求会持续“爆炸”式增长,但如果像 DeepSeek 这样低成本、高效率的大模型越来越多,企业在 2026 年后对 GPU 的采购策略就会出现“效率优先”的转变。
从顶尖学术机构到全球应用市场双线“登顶”
DeepSeek-R1 的声名不仅在工业界和资本市场搅动风云,也在学术界迅速扩张。正如 a16z(Andreessen Horowitz)合伙人、Mistral 董事会成员 Anjney Midha 所说:“从斯坦福到麻省理工,DeepSeek-R1 几乎一夜之间就成了美国顶尖大学研究人员的首选模型。”
这意味着,在前沿学术研究场景,DeepSeek-R1 已经取得了极高的认可度。

另一方面,在消费端的热度也不断攀升。DeepSeek 的官方 App 如火箭般超越了 ChatGPT 的官方应用,强势登顶 App Store;在谷歌上的搜索指数也全面赶超 ChatGPT。某种意义上,这预示着 DeepSeek 在通用用户市场的影响力可能会延续甚至进一步扩大。
如果还要为这种爆火寻找佐证,那么来自投资大佬 Marc Andreessen(a16z 创始人)的评价堪称“核弹级背书”——“DeepSeek R1 是 AI 的斯普特尼克时刻。这是我见过最惊艳、最令人印象深刻的突破之一——而且是开源的,是对全世界的一种深刻馈赠。”
斯普特尼克时刻(Sputnik moment)源自1957年苏联发射第一颗人造卫星”斯普特尼克1号”,象征着一个划时代的技术突破,引发了全球科技竞赛的新格局,现在常用来比喻某个领域出现的颠覆性技术进展。
“性价比之王”:开源、大模型与训练范式的变革
DeepSeek-R1 的成功并非孤立。回顾其 V2、V3 版本的迭代历史,在多项评测中,DeepSeek V3 均达到了开源领域的 SOTA(最先进)水准,甚至一度超越 Llama 3.1 405B,在一些能力上可与 GPT-4o等顶级大模型正面硬碰硬。

而这背后的核心突破,在于两点:
1. 混合专家架构(MoE) 的深度应用;
2. 以强化学习(RL)为主导 的训练范式。
这样的技术路径不仅极大降低了对海量标注数据的依赖,同时还保证了模型的性能。结果是,DeepSeek-R1 的训练总成本控制在约 550 万美元——只有 Anthropic、OpenAI 那些“豪门”动辄 10 亿美元训练成本的一个零头,堪称“大模型性价比之王”。
也难怪业内都在惊叹 DeepSeek 对 AI 民主化的贡献。最新数据显示,R1 在 HuggingFace 上以 14.9 万次下载量夺得开源模型下载冠军,其搜索和问答功能被众多用户评价“已经超越了 OpenAI 和 Perplexity”。
而真正让广大开发者欢呼的是——R1 的成本只有竞品的 3%-5%。对于那些苦于 AI 部署成本、想要快速打造高质量 APP 的初创企业,DeepSeek 等同于递上了通往未来的钥匙。
中国机会:梁文锋的“野心”与开源哲学
微软 CEO 纳德拉在达沃斯论坛上的一句话颇有意味:“必须认真对待中国 AI 的发展。”
诚然,DeepSeek 的这次爆发再次印证——即使曾经的大模型话语权主要集中在美国,如今中国企业也可能在创新层面拔得头筹。
面对外界对 DeepSeek 的追捧与各种“封神”言论,DeepSeek CEO 梁文锋在采访中表现得相当冷静。他坦言,团队最初并没打算“刻意搅动”市场,只是按照自己对成本和定价的理解去做事,结果却意外引发了一场大模型的价格战。
对于“中国更多擅长做应用而非创新”的质疑,梁文锋认为,这与中国长期缺席底层技术创新有关。“过去三十多年 IT 浪潮里,我们基本是跟随,没有真正参与创新。” 但 DeepSeek 想扮演的角色,是一个能够“跳进创新者的游戏”的玩家。
在“开源是否会丢失护城河”的问题上,他的观点颇具前瞻性:在颠覆性技术面前,闭源并不能形成长期壁垒,真正的护城河在团队和文化的持续创新能力。“开源是我们的文化选择,为了让更多人低门槛用上大模型。”
在梁文锋看来,被别人跟随、被社区共创,反而是一种荣誉。
大模型“没有护城河”背后的中国机遇
开源社区与许多技术博主纷纷指出,DeepSeek R1 证明了大模型可能真的没有“护城河”。它用最少的资金,实现了之前需要天价 GPU 资源和大量资本才能达到的效果。
这意味着,任何企业或开发者都能更轻松地打造高质量的 AI 应用,而中国团队又擅长在应用层面进行爆发式创新。可以预见,DeepSeek 给中国企业提供了新的出海窗口:用较低成本快速构建并迭代产品,抢先占据全球市场。
一位硅谷投资人最近在社交网络上发文称:“一周前,没人看好那些只是简单封装 GPT 的应用公司。今天 DeepSeek 发布了 R1,明天可能又会出现一个新的领先模型。可要让几百万人习惯性地使用某一款产品,这才是竞争壁垒。ChatGPT 之所以起步快,不是因为模型性能碾压,而是因为它用起来够简单。”
这番话点出一个关键:模型迭代的速度越来越快,尤其在国家层面,大模型更像是举国战略的一部分。谁也保不准下一次“黑马”会不会在两周后就出现。用户习惯、使用门槛这些要素,才是把大众牢牢绑住的强大护城河。

从在 DMV排队时的大妈们口耳相传,到资本市场的惊天动荡,再到学术界的争相追捧和应用市场的热烈欢迎,DeepSeek-R1 的横空出世无疑打破了我们对 AI 产业格局的固有想象。它背后的故事既是中国公司崛起的一个缩影,也是全球 AI 浪潮再度洗牌的写照。
面向未来,DeepSeek 带来的不仅是对技术路线的启示,也是一种全新的思考方式——在开源与合作的浪潮中,任何一家公司都不可能永远独占鳌头。当大模型成本极大降低,中国公司在应用层面多年的积累与爆发力有了更广阔的舞台。
或许,这才是 DeepSeek-R1 真正带来的深远意义:让世界看到,中国也可以引领科技创新潮流,这一机遇不仅属于中国,更属于所有愿意勇敢拥抱新技术的群体。
正如 Marc Andreessen 所言:“DeepSeek R1 是 AI 的斯普特尼克时刻。” 这个时刻既是警钟,也是礼物。
(本文仅代表作者个人观点,不代表所属机构立场。)
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






